书籍豆瓣链接:《高性能MySQL》
开始学习时间:
预计完成时间:
实际完成时间:
MySQL架构
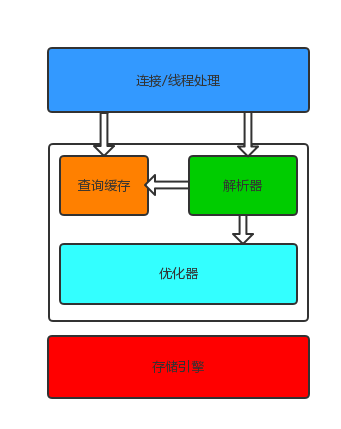
架构
服务层
负责链接管理(客户端与服务器半双工)、授权认证、安全。维护一个连接池,使用用户名和密码或SSL进行认证。
查询优化
负责解析查询(编译SQL),并进行优化。对于SELECT语句,先查询缓存。存储过程、触发器、视图都在这一层。
存储层
负责存储数据、提取数据、开启一个事务等等。存储引擎通过api与上层进行通信,api屏蔽了不同存储引擎之间的差异。
隔离性
针对隔离性遇到的问题如下:
-
脏读:读到了别的事务回滚前的脏数据
-
不可重复读:事务A前后两次读取数据不一致(事务B改变了数据,update和delete)
-
幻读:事务A首先根据索引得到N条数据,再次搜索发现有N+M条数据了(事务B进行了insert
-
丢失更新:同时更新数据,一方数据被覆盖
隔离级别
- read uncommitted(未提交读)
解决了丢失更新问题
- read committed(提交读)
解决了脏读的问题
- repeatable read(可重复读)
解决了不可重复读问题,解决了幻读问题
- serializable(序列化)
解决丢失更新问题
乐观锁和悲观锁
乐观锁
获取数据不加锁
更新数据判断数据是否被修改,如果修改不更新
适合于多读的机制,可以提高吞吐量
一般使用:version方式和CAS方式
version方式
提交版本必须大于记录当前版本才能执行更新,
CAS方式
compare and swap或者compare and set,是一种有名无锁算法,不使用锁的情况下(线程不会被阻塞)实现多线程之间的变量同步。
涉及到三个操作数:内存值、预期值和新值
- 需要读写的内存值 V
- 进行比较的值 A
- 你写入的新值 B
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
1 | int compare_and_swap (int* reg, int oldval, int newval) |
悲观锁
每次获取数据都加锁
依赖数据库的锁机制,无法保证外部系统不会修改数据
存储引擎
InnoDB
MVCC支持高并发,默认可重复读,通过间隙锁策略防止幻读
MyISAM
MyISAM会将表存储在两个文件:数据文件和索引文件,不支持事务和行级锁
崩溃后无法安全回复,对于只读,容忍修复操作,小表可以用MYISAM
索引特性,即使是BLOB和TEXT等长字段,也可以基于前500字符创建索引,支持全文索引
myisam的数据分布,myisam的数据根据插入的顺序存储在磁盘上,行号从0开始递增
myisam的索引的叶子节点存的是行指针
Schema与数据类型优化
数据类型
整数类型
整数存储,分为TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT,分别使用8,16,24,32,64位存储空间
整数计算使用64位的BIGINT
实数类型
FLOAT 4字节
DOUBLE 8字节,使用DOUBLE作为浮点计算类型
DECIMAL(M,N) 精确计算代价高,转为浮点不精确,宜转成BIGINT
字符串类型
VARCHAR 可变长字符串,比定长节省空间,额外存字符串长度
CHAR 定长字符串
BLOB 二进制存储 二进制数据
TEXT 字符存储 有字符集和排序规则
BLOB和TEXT不能索引全部长度字符串,应该避免
- ENUM
优点 代替常用字符串,MYSQL会保存一个映射表,每个值的位置-字符串
缺点 字符串列表固定,添加或删除字符串必须使用ALTER TABLE
日期和时间类型
- DATETIME
8字节,与时区无关,保存大范围值
- TIMESTAMP
保存1970.1.1(格林尼治标准时间)以来的秒数,4字节,与时区有关
位数据类型
BIT MYSQL把bit当字符串,b’00111001’存0x57
SET 需要ALTER TABLE
选择标识符
整数性能好,可以使用AURO INCREMENT
不宜使用ENUM SET
不宜使用字符串,占空间,随机字符串造成页分裂
类型选择策略
-
尽量选择可以正确存储数据的最小数据类型
-
使用操作简单的数据类型。字符串有字符集和校对规则,操作代价比整型大。使用MYSQL内建类型,而不是字符串存储日期和时间,使用整型存储IP地址
-
尽量避免NULL,给默认值
schema设计陷阱
很宽的表,只使用一小部分列,性能差
避免太多的关联
ENUM添加枚举需要ALTER TABLE,不如新建一个枚举表
范式和反范式
数据库三范式
- 第一范式 字段原子不可分
数据库的每一列都是不可分割的原子数据项,不能是数组或JSON串
- 第二范式 有主键,非主键完全依赖主键
主键是关注人ID+被关注人ID,关注人信息部分依赖主键
- 第三范式 非主键直接依赖主键,不存在传递依赖
员工表有个字段是部门ID,部门信息不直接依赖员工ID,不应该存在于员工表
范式优缺点
优点 表更小,没有重复冗余数据,更新更快
缺点 需要关联
反范式优缺点
优点 数据在一张表里,很好地避免关联,更好地使用索引
缓存和汇总表
高性能的索引策略
索引基础
b树索引
- 数据结构
-
B树
树中每个节点最多包含m个孩子,根节点至少有2个子节点,非根非叶节点至少有m/2个子节点
有n个关键字的父节点,拥有n+1个子节点,每个节点的关键字记录数据在磁盘中的位置
-
B+树
叶子节点包含了全部的关键字信息,所有的数据仅存在叶子节点
-
为什么B+树更适合做文件或者数据库索引
B+树非叶子节点不存数据的地址信息,B+树叶子节点有链表结构,方便范围查询
-
B*树
非叶子节点加链表,非叶子节点关键字个数至少2/3M
- 支持的查询
创建一个包含多列的索引,支持以下查询
- 全值匹配,和索引中所有列匹配
- 匹配索引第一列
- 匹配索引第一列的前缀
- 匹配索引第一列的范围
- 匹配索引第一列,匹配索引第二列的范围
- 只访问索引列的查询(索引覆盖)
- 索引的限制
- 必须从最左列开始查找
- 不能跳过索引的列
- 某一列范围查询,右边所有列都无法使用索引查找
- 优点
- 减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 随机io变顺序io
哈希索引
计算所有列的哈希值,为key,指针为为v
特性
- innodb内置自适应哈希索引,给频繁使用的b树索引加一个哈希索引
- 不支持部分列查询,无法用于排序
- 只包含哈希值和行指针,不存储字段值,无可避免的要读取行
空间数据索引
TODO
全文索引
TODO
索引优化
单列索引
索引的选择性 不重复的索引值和数据表记录总数的比值,比值越高查询效率越高
计算 SELECT COUNT(DISTINCT column)/COUNT (*) FROM
前缀索引 很长字符串列建立索引索引,索引大且慢,在保证索引选择性的情况下,使用字符串前缀作为索引
多列索引
- 索引合并策略
对多个索引做相交操作(AND),需要一个包含所有相关列的多列索引
对多个索引做联合操作(OR),需要耗费大量的CPU和内存资源在算法的缓存,排序和合并操作上,可能还不如全表扫描
- 选择合适的索引列顺序
选择性最高的列放在最前列效率最好
聚簇索引
当表有聚簇索引,数据行实际上存放在叶子页
- 优点
可以键值相邻的数据保存在一起
数据访问更快
覆盖索引扫描的查询可以直接使用主键值
- 缺点
更新聚簇索引列的代价很高,强制innodb将每个被更新的行移动到新的位置,插入造成页分裂
- 按主键顺序插入行
最简单的方法是使用auto increment自增列
使用UUID作为聚簇索引,索引插入完全随机,写入是乱序的,不得不频繁做页分裂操作
覆盖索引
索引包含所有需要查询的字段值,称为覆盖索引
- 优点
索引条目远小于数据行大小
索引按列值顺序存储的,支持范围查询,比访问磁盘的io少得多
二级索引叶子节点保存主键值,如二级索引能覆盖查询,避免主键索引的二次查询
- 延迟关联
如索引无法覆盖,可使用二级索引查出id集,然后使用聚簇索引获取数据
索引排序
-
只有索引的列顺序和ORDER BY子句的顺序完全一致,并且所有列的排序方向一致或相反
-
关联多张表,ORDER BY子句字段都是第一张表
-
ORDER BY子句满足最左前缀
-
WHERE子句使用常量过滤,和ORDER BY子句一起,满足最左前缀
冗余和重复索引
-
重复索引 创建多个相同列,索引类型相同的索引
-
冗余索引 有了index(a,b),再创建index(a),或者包含主键的耳机索引
-
需要冗余索引场景
为保证单查a的效率,已有index(a,b,c),仍新建index(a)
索引与锁
Innodb只有访问行的时候才会加锁,而索引能减少innodb访问的行数
在主键索引上使用排他锁,在二级索引上使用共享锁
Explain
type 访问类型
all 全表扫描
index 另外一种形式的全表扫描,扫描顺序按照索引的顺序,然后根据索引回表查数据
ref 查找列使用索引而且不为主键和unique
req_eq 查找结果唯一
const 将主键放到where后面作为条件查询,将查询转化为常量
extra
using filesort 无法利用索引完成排序操作
using index 表示使用覆盖索引,不用回表
using where 表示优化器需要通过索引回表查询数据
索引案例
支持多种过滤条件
选择性低,但是几乎所有查询都能用到的索引,比如sex,用作索引前缀
如果没用到sex,可以加上sex in [‘male’, ‘female’],匹配最左前缀,复用索引而不是建立大量的组合索引
由于索引遇到范围查询,后续字段无法使用索引,可以使用IN代替范围查询
但是IN查询优化器会转化成组合,应避免嵌套IN
优化排序
- 索引排序
文件排序对于小数据集很快,对于选择性低的列,使用索引做排序
- 深度分页
一个策略是延迟关联,使用覆盖索引返回需要的主键,根据主键关联原表获取行
查询性能优化
- 查询性能优化方向
- 好的库表结构设计
- 好的索引优化策略
- 好的查询语句
排查思路
是否向数据库请求了不需要的数据
- 查询不需要的记录
查询后面加上LIMIT
- 多表关联时返回全部列
修改为select tb.*返回某个表全部列
- 总是取出全部列,无法完成索引覆盖
不使用select *
- 重复查询相同的数据
使用缓存
MYSQL是否扫描了额外的记录
- 响应时间
响应时间 = 服务时间 + 排队时间
服务时间 数据库处理查询的时间
排队时间 等待io等待锁的时间
- 扫描的行数
使用explain type返回where条件的三个等级
-
type=ref extra=,主键索引中使用where过滤不匹配记录,存储引擎完成
-
type=ref extra=using index,使用覆盖索引扫描和过滤,服务器层完成
-
type=all extra=using where,数据表返回数据,服务器层完成
- 返回的行数
重构查询
切分查询
MYSQL扫描内存中数据快,响应数据给客户端慢,将一条大的语句一次性完成,可能会造成
-
一次锁住很多数据
-
占满整个事务日志
-
耗尽系统资源
-
阻塞很多小但重要的查询
分解关联查询
在应用程序进行关联,每一个表进行一次单表查询,优势
-
让缓存效率更高,应用方便缓存单表查询结果
-
单个查询减少锁的竞争
-
应用层做关联,更容易对数据库进行拆分,高性能和扩展
-
使用单表查询获得的ids进行IN查另一个表,比随机关联查询性能更高
-
减少冗余记录的查询
-
相当于用应用层的哈希关联,替代mysql的嵌套循环关联
查询执行的基础
查询执行流程
-
客户端发送一条查询给服务器
-
先检查查询缓存,未命中进入下一步
-
服务器端进行SQL解析(解析器),预处理器(预处理器),查询优化器生成对应执行计划
-
查询执行引擎调用存储引擎API执行计划
-
结果返回客户端
查询优化处理
- 等价变换简化规范表达式
如where子句顺序
- MIN,MAX,COUNT
转化为常量
- 等值传播
等值关联的字段,WHERE条件会传递到另一个列上,无需写两个
- 列表IN
先排序列表,在二分搜索,IN是logn,OR是n**??为何是logn,不是都是nlogn**
- 执行关联查询
执行嵌套循环关联操作(全外连接无法通过嵌套循环和回溯的方式完成,MYSQL没有全外连接)
优化特定类型查询
- COUNT()
- COUNT(*) 不会扩展所有的列,直接忽略所有的列统计行数
MYISAM是表级锁,不会有并发操作,将表的总行数记录下来
INNODB选择最小的非聚簇索引来扫表,前提是没有where和groupby
-
COUNT(col) 统计某个列值数量,要求列值非NULL
-
COUNT(1)和COUNT(*)没有区别
- 优化关联查询
确保ON或USING子句中的列上有索引
确保groupby orderby只涉及一个表中的列
- 优化LIMIT分页
- 使用索引覆盖扫描,而不是查询所有列
不能解决深度分页
-
使用延迟关联
-
查询转换为已知位置查询,offset转换为<>
- 优化UNION查询
通过创建并填充临时表的方式来执行UNION
UNION会给临时表加DISTINCT选项,导致整个临时表做唯一性检查
除非需要去重,否则一定要使用UNION ALL